
[レコメンド] ピアソン相関を用いた類似度の計測
こんにちは、@yoheiMuneです。
先日の「ユークリッド距離を用いた類似性の測定」に続き、 ピアソン相関という仕組みを用いた類似度の計測方法をブログに書きたいと思います。

② 滝の中で
③ スターウエアーズ
④ サンバでGO
⑤ 世界の端でアイっと叫ぶ
⑥ここはどこ
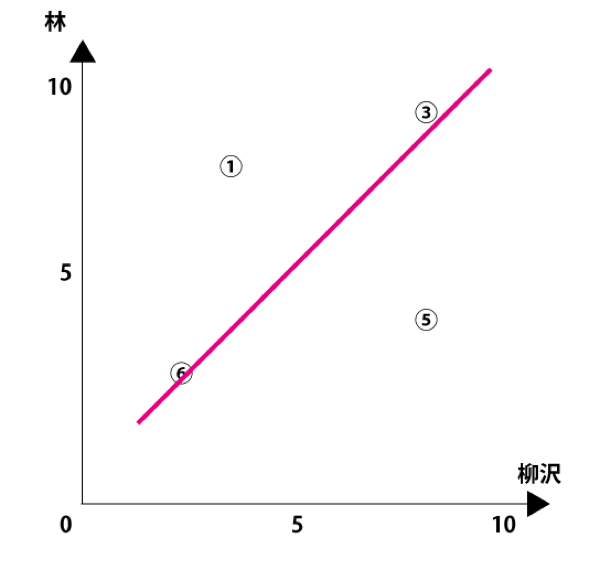
そしてプロットされた各点が最適曲線に近いほど、類似度が高いと判断します。もし全ての点が直線上にある場合には、 2人の映画に対する評価は全く同じで、相関が1となります。
図解した内容は理解しやすいのですが、計算式が直感的でない感じで。 自分も詳細に理解できている訳ではないので、間違えていたらごめんなさい。次ではピアソン相関を求めるプログラムを掲載します。
Javaですが、将来的にはRとかで書きた♪(´ε` )
このピアソン相関を用いて、ユーザーごとの類似度を計測してみた結果が以下となります。
あと負の相関が出ている組み合わせもあるようですね。
例えば今回のようなデータ評価については、辛口評価者と甘口評価者の好みが同じであったとしても、 ユークリッド距離では類似度の高い人とは判断されませんが、ピアソン相関では辛口と甘口の誤差を考慮して、類似度の高い人として判定することができたりします。
類似度の計測手法は色々と知っていて損はなさそうで、使い分け出来るようになれれば良いなぁという思いです。
- Amazon:集合知プログラミング
類似度の計測が出来ると、レコメンドシステムの簡単なものは作れるので、 今後のブログでは類似度の計測を用いたレコメンドシステムを作ってみたいと思います。
最後までご覧頂きましてありがとうございました。
先日の「ユークリッド距離を用いた類似性の測定」に続き、 ピアソン相関という仕組みを用いた類似度の計測方法をブログに書きたいと思います。
ピアソン相関を用いた類似度の計測
先日の記事で利用した以下の、ユーザーの映画に対する評価データを分析して、 嗜好が近しい人をピアソン相関というものを使って導きだしてみたいと思います。■ユーザー
林、 伊藤、 大原、 柳沢、 久保、 大内、 斉藤■映画
① パイレーツinブリリアン② 滝の中で
③ スターウエアーズ
④ サンバでGO
⑤ 世界の端でアイっと叫ぶ
⑥ここはどこ
■ユーザーの映画に対する評価(例)
| ① | ② | ③ | ④ | ⑤ | ⑥ | |
|---|---|---|---|---|---|---|
| 林 | 7 | 8 | 4 | 3 | ||
| 伊藤 | 2 | 3 | 5 | 7 | 10 | |
| 大原 | 5 | 4 | 5 | 1 | ||
| 柳沢 | 4 | 10 | 9 | 9 | 3 | |
| 久保 | 10 | 4 | 3 | 8 | ||
| 大内 | 7 | 7 | 2 | 3 | ||
| 斉藤 | 10 | 10 | 1 | 8 |
※空欄は、評価していないことを示します。
上記のデータはでっちあげであり、実際のデータではありません。
ピアソン相関を用いた類似度の計測とは
ピアソン相関を用いた類似度の計測とは、例えば以下の2人の評価を2次元にプロットした場合に、 全ての点に出来るだけ近い直線(最適直線)を引きます。そしてプロットされた各点が最適曲線に近いほど、類似度が高いと判断します。もし全ての点が直線上にある場合には、 2人の映画に対する評価は全く同じで、相関が1となります。
図解した内容は理解しやすいのですが、計算式が直感的でない感じで。 自分も詳細に理解できている訳ではないので、間違えていたらごめんなさい。次ではピアソン相関を求めるプログラムを掲載します。
ピアソン相関を求める
ピアソン相関を求めるプログラムが以下となります。Javaですが、将来的にはRとかで書きた♪(´ε` )
/**
類似度計測:ピアソン相関。
@param prefs 分析対象データ(Map<ユーザー名, Map<映画名, 評価値>>)
@param person1 比較対象ユーザー1
@param person2 比較対象ユーザー2
*/
protected double simPearson(Map<String, Map<String, Double>>prefs, String person1, String person2) {
// 2人とも評価しているアイテムリストを生成する
List<String> movieList = new ArrayList<String>();
Set<String> user1MovieList = rawDataMap.get(person1).keySet();
Set<String> user2MovieList = rawDataMap.get(person2).keySet();
for (String movie : user1MovieList) {
if (user2MovieList.contains(movie)) {
movieList.add(movie);
}
}
// もし2人に共通のアイテムが無ければ、類似性なしと判断する
if (movieList.size() == 0) {
return 0.0;
}
// 全ての嗜好を合計します
Map<String, Double> user1Map = rawDataMap.get(person1);
Map<String, Double> user2Map = rawDataMap.get(person2);
double sum1 = 0.0, sum2 = 0.0;
for (String movie : movieList) {
sum1 += user1Map.get(movie);
sum2 += user2Map.get(movie);
}
// 平方を合計します
double sum1Sq = 0.0, sum2Sq = 0.0;
for (String movie : movieList) {
sum1Sq += user1Map.get(movie) * user1Map.get(movie);
sum2Sq += user2Map.get(movie) * user2Map.get(movie);
}
// 積を合計します
double pSum = 0.0;
for (String movie : movieList) {
pSum += user1Map.get(movie) * user2Map.get(movie);
}
// ピアソンによるスコアを計算します
int n = movieList.size();
double num = pSum - (sum1 * sum2 / n);
double den = Math.sqrt((sum1Sq - Math.pow(sum1, 2) / n) * (sum2Sq - Math.pow(sum2, 2) / n));
if (den == 0) return 0.0;
return num / den;
}
このピアソン相関を用いて、ユーザーごとの類似度を計測してみた結果が以下となります。
※ 値は前回の記事同様にランダムに生成しているため、上記表の結果とは異なります。
林 伊藤: 0.1345345587992625 林 大原: -0.08610616978192351 林 柳沢: 0.6546536707079772 林 久保: -0.9941916256019201 林 大内: -1.0 林 斉藤: 1.0 伊藤 大原: -0.11294649172467833 伊藤 柳沢: -0.897827245004404 伊藤 久保: -0.43355498476206034 伊藤 大内: -0.9933992677987827 伊藤 斉藤: -0.9607689228305194 大原 柳沢: 0.6286185570937121 大原 久保: 0.3711537444790452 大原 大内: 1.0 大原 斉藤: 1.0 柳沢 久保: 0.0 柳沢 大内: 1.0 柳沢 斉藤: 0.9912407071619259 久保 大内: 1.0 久保 斉藤: 1.0 大内 斉藤: 0.7997867519620918今回のデータでは情報が少なくて、2人ともに評価している映画が1本とか2本とかで、その結果、相関が1になったりする部分もあるようです。
あと負の相関が出ている組み合わせもあるようですね。
ユークリッド距離とピアソン相関
前回の記事で紹介させて頂いたユークリッド距離と今回の記事のピアソン相関ですが、 どちらも類似度を求める方法ではあるものの、結果は異なります。 類似度の計測方法は他にも色々とある(とのこと)ですが、どれを用いるかはアプリケーション次第です。例えば今回のようなデータ評価については、辛口評価者と甘口評価者の好みが同じであったとしても、 ユークリッド距離では類似度の高い人とは判断されませんが、ピアソン相関では辛口と甘口の誤差を考慮して、類似度の高い人として判定することができたりします。
類似度の計測手法は色々と知っていて損はなさそうで、使い分け出来るようになれれば良いなぁという思いです。
参考資料
この記事では、以下の書籍の内容を参考にしております。良き情報に感謝です。- Amazon:集合知プログラミング
最後に
今回はピアソン相関を用いた類似度計測の内容と実装方法を紹介させて頂きました。類似度の計測が出来ると、レコメンドシステムの簡単なものは作れるので、 今後のブログでは類似度の計測を用いたレコメンドシステムを作ってみたいと思います。
最後までご覧頂きましてありがとうございました。



