[HTML5] Web Speech APIに入門
こんにちは、@yoheiMuneです。
7月になってやっとブログを書く余裕が出てきた(´∀`∩)〜〜。 今日は、Chromeでも最近使えるようになったWeb Speech APIについて入門記事を書きたいと思います。

Web Speech APIには大きく2つの機能があり、音声認識とテキストスピーチです。 音声認識とはその名の通りユーザーがしゃべった内容を認識して文字にしてくれる機能です。 テキストスピーチはMacのsayコマンドのようなもので、指定した文字列をPCが発音してくれます。
本機能の利用用途としては、例えば以下のようなものが考えられます。
Web Speech APIのサポート状況は、Can I Useによると以下の通りです。
 Web Speech API | Can I Use
Web Speech API | Can I Use
なんとiPhoneでも部分的に使えるというのが驚きです(筆者が試した時点では英語のテキストスピーチができました)。
以降の章では具体的な使い方を紹介します。
 http://yoheim.net/labo/html5/web-speech-api.html
http://yoheim.net/labo/html5/web-speech-api.html
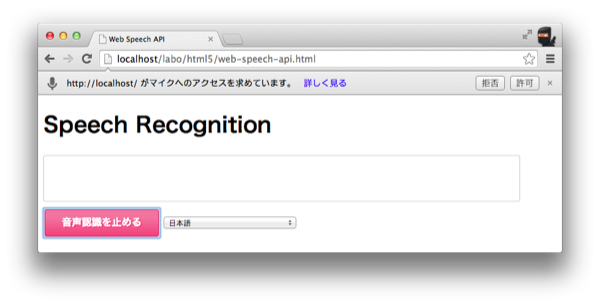
実際には「音声認識を始める」ボタンを押すと、Chrome上でマイクの利用許可が表示されます。 ここで「許可」を押すことでJavaScriptからマイクを利用することができるようになります。
 実装内容は以下の通りです。
JavaScriptを通してこんな感じで簡単に音声認識が行えるなんて、素敵ですね。
実装内容は以下の通りです。
JavaScriptを通してこんな感じで簡単に音声認識が行えるなんて、素敵ですね。
 http://yoheim.net/labo/html5/web-speech-api.html
http://yoheim.net/labo/html5/web-speech-api.html
具体的な実装内容は以下の通りです。
こちらのコードもhttp://jsdo.it/y.munesada/iUgpに置きました。
 http://yoheim.net/labo/html5/web-speech-api.html
http://yoheim.net/labo/html5/web-speech-api.html
実装は以下のように簡単に行うことができます。
今後のブログでもフロントエンド最前線(またはそれに近い)情報をお送りできたらと思っています。ぜひ、本ブログのRSSやTwitterをフォローして頂けると幸いです ^ ^。
最後までご覧頂きましてありがとうございました!
7月になってやっとブログを書く余裕が出てきた(´∀`∩)〜〜。 今日は、Chromeでも最近使えるようになったWeb Speech APIについて入門記事を書きたいと思います。
Special Thanks to https://flic.kr/p/7fADmS
目次
Web Speech APIとは
Web Speech APIはW3Cコミュニティグループによって策定されている仕様で、Web Speech API Specificationに仕様が掲載されています。この仕様書はリンク先にも記載の通り「It is not a W3C Standard nor is it on the W3C Standards Track(このドキュメントはW3C標準でもなければW3Cの標準トラックに則ったものでもない)」とW3C標準ではありません。しかしWebkitやBlinkエンジンを積んだいくつかのブラウザで既に利用可能となっています。Web Speech APIには大きく2つの機能があり、音声認識とテキストスピーチです。 音声認識とはその名の通りユーザーがしゃべった内容を認識して文字にしてくれる機能です。 テキストスピーチはMacのsayコマンドのようなもので、指定した文字列をPCが発音してくれます。
本機能の利用用途としては、例えば以下のようなものが考えられます。
- 声によるWeb検索(AndroidやiPhone Siriのような機能)
- 声によるマシンへの命令
- Inputフィールドへの声による入力
- ゲーム
- など
Web Speech APIのサポート状況は、Can I Useによると以下の通りです。
(執筆時点でのサポート状況です。最新状況はリンク先をご確認ください。)
Web Speech API | Can I UseなんとiPhoneでも部分的に使えるというのが驚きです(筆者が試した時点では英語のテキストスピーチができました)。
以降の章では具体的な使い方を紹介します。
音声認識を使ってみる
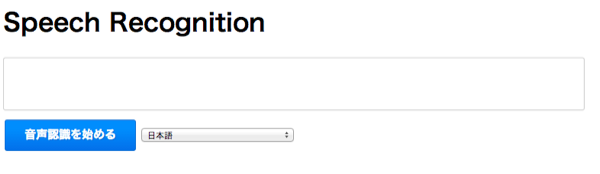
まずは一番簡単な例で、音声認識を行う実装例を紹介します。以下の例では、ボタンを押して音声認識を始めて、もう一度ボタンを押して音声認識を終了します。 認識された音声は枠の中に表示されます。
http://yoheim.net/labo/html5/web-speech-api.html実際には「音声認識を始める」ボタンを押すと、Chrome上でマイクの利用許可が表示されます。 ここで「許可」を押すことでJavaScriptからマイクを利用することができるようになります。
実装内容は以下の通りです。
JavaScriptを通してこんな感じで簡単に音声認識が行えるなんて、素敵ですね。
// 音声認識機能
var recognition;
// 音声認識中か否かのフラグ
var nowRecognition = false;
// 音声認識を開始するメソッド
function start () {
// 音声認識のインスタンスを作成します
recognition = new webkitSpeechRecognition();
// 利用言語を選択します(Chromeでは日本語も使えます)
recognition.lang = document.querySelector('#select1').value; // en-US or ja-JP
// 音声認識が終了したら結果を取り出すためのコールバック
recognition.onresult = function (e) {
if (e.results.length > 0) {
var value = e.results[0][0].transcript;
document.querySelector('#area1').textContent = value;
}
};
// 音声認識開始
recognition.start();
nowRecognition = true;
};
// 音声認識を停止するメソッド
function stop () {
recognition.stop();
nowRecognition = false;
}
// ボタンアクションを定義
document.querySelector('#btn1').onclick = function () {
// unsupported.
if (!'webkitSpeechRecognition' in window) {
alert('Web Speech API には未対応です.');
return;
}
if (nowRecognition) {
// 音声認識終了
stop();
this.value = '音声認識を始める';
this.className = '';
} else {
// 音声認識開始
start();
this.value = '音声認識を止める';
this.className = 'select';
}
}
ポイントとしては「webkitSpeechRecognition」を使って音声認識の開始や終了、そして結果の取り出しを行う点です。
上記デモコード全体はhttp://jsdo.it/y.munesada/mPucに置きました。音声認識を使ってみる(継続的な認識を行う)
続いて上記の機能を少し発展させて、音声認識を継続的に行う方法を紹介します。Googleもデモを用意していますが、ユーザーがしゃべっている間にもドンドンと音声認識の結果を取得することが出来ます。
http://yoheim.net/labo/html5/web-speech-api.html具体的な実装内容は以下の通りです。
// 音声認識機能
var recognition;
var nowRecognition = false;
// 確定した結果を表示する場所
var $finalSpan = document.querySelector('#final_span');
// 音声認識中の不確かな情報を表示する場所
var $interimSpan = document.querySelector('#interim_span');
// 音声認識開始のメソッド
function start () {
recognition = new webkitSpeechRecognition();
recognition.lang = document.querySelector('#select2').value;
// 以下2点がポイント!!
// 継続的に処理を行い、不確かな情報も取得可能とする.
recognition.continuous = true;
recognition.interimResults = true;
// 音声結果を取得するコールバック
recognition.onresult = function (e) {
var finalText = '';
var interimText = '';
for (var i = 0; i < e.results.length; i++) {
// isFinalがtrueの場合は確定した内容
// 仕様書では「final」という変数名だが、Chromeでは「isFinal」のようです.
if (e.results[i].isFinal) {
finalText += e.results[i][0].transcript;
} else {
interimText += e.results[i][0].transcript;
}
}
$interimSpan.textContent = interimText;
$finalSpan.textContent = finalText;
};
recognition.start();
nowRecognition = true;
};
// 音声認識を止めるメソッド
function stop () {
recognition.stop();
nowRecognition = false;
}
// ボタンアクションの定義
document.querySelector('#btn2').onclick = function () {
// unsupported.
if (!'webkitSpeechRecognition' in window) {
alert('Web Speech API には未対応です.');
return;
}
if (nowRecognition) {
stop();
this.value = '音声認識を継続的に行う';
this.className = '';
} else {
start();
this.value = '音声認識を止める';
this.className = 'select';
}
}
1つ前のサンプルと違う点は、recognition.continuous = trueとrecognition.interimResults = trueを設定して認識中の内容も取得可能とする点と、音声取得結果についてe.results[i].isFinalの判定を用いて、それが確定した情報なのか否かを判定している点です。こちらのコードもhttp://jsdo.it/y.munesada/iUgpに置きました。
テキストスピーチ
最後にテキストスピーチを扱います。今までの例とは異なり、ブラウザがしゃべります。
http://yoheim.net/labo/html5/web-speech-api.html実装は以下のように簡単に行うことができます。
document.querySelector('#btn3').onclick = function () {
// unsupported.
if (!'SpeechSynthesisUtterance' in window) {
alert('Web Speech API には未対応です.');
return;
}
// 話すための機能をインスタンス化して、色々と値を設定します.
var msg = new SpeechSynthesisUtterance();
msg.volume = 1;
msg.rate = 1;
msg.pitch = 2;
msg.text = document.querySelector('#text1').value; // しゃべる内容
msg.lang = document.querySelector('#selectVoice').value; // en-US or ja-UP
// 終了した時の処理
msg.onend = function (event) {
console.log('speech end. time=' + event.elapsedTime + 's');
}
// テキストスピーチ開始
speechSynthesis.speak(msg);
};
SpeechSynthesisUtteranceの詳細は、5.2 The SpeechSynthesis Interface | 仕様書で確認することができます。
Chromeだと日本語も発音してくれるのでとてもいい感じです!
具体的なコードは、http://jsdo.it/y.munesada/8qn5に置きました。最後に
私が初めてWeb Speech APIについて知ったのは、5jcupに応募された作品を見た時でした。まだまだ知らない機能がいっぱいあるなーと思い、フロントエンドとして活動していますがまだまだ勉強不足と痛感した次第でした。今後のブログでもフロントエンド最前線(またはそれに近い)情報をお送りできたらと思っています。ぜひ、本ブログのRSSやTwitterをフォローして頂けると幸いです ^ ^。
最後までご覧頂きましてありがとうございました!